
티스토리 뷰

TEMP 테이블

TDEPT 테이블

자료의 조회
데이터베이스의 넓은 영역 중 자료검색과 관련된 부분이 많은 부분을 차지한다. 자료검색을 위한 가장 기본이 되고 중요한 부분이다.
1. SELECT 구조
자료의 조작을 위하여 필요한 DML 은 크게 4가지가 있다.
조회(SELECT), 입력(INSERT), 수정(UPDATE), 삭제(DELETE)
가장 많은 빈도로 사용되는 DML은 SELECT 문장이다. SELECT와 짝을 이루어 기술되어야 하는 절이 있는데 FROM 절이다. FROM절(테이블)에서 SELECT(컬럼)하여 읽어 올 것인가는 반드시 기술되어야 하는 필수 사항이다.
그 외로 SELECT 문장에서 기술되는 절은 다음과 같다.
WHERE : 테이블에 조건을 부여하여 제한할 때 사용
GROUP BY : GROUP 함수를 사용하여 자료를 GROUP 지을 때 사용
HAVING : GROUP 된 결과에 조건을 부여하여 제한할 때 사용 (GROUP BY 절이 있을 경우에만 사용)
ORDER BY : 결과를 정렬할 때 사용
2. SELECT 산술 연산
DML을 이용하여 계산기의 기본 산술 연산이 가능하다. 연산 시 순서와 부호는 계산기와 동일하다.
SELECT EMP_ID
FROM TEMP;
-- TEMP 테이블에서 이름과 월급여액을 조회하라.
SELECT EMP_NAME
, SALARY/12
FROM TEMP;
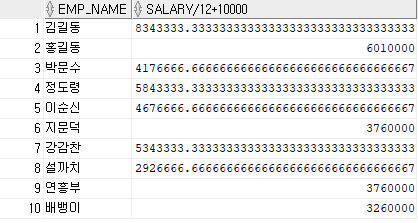
-- TEMP 테이블에서 이름과 월급여액에 10000을 더해 조회하라.
SELECT EMP_NAME
, SALARY/12 + 10000
FROM TEMP;


3. NULL 사용
NULL은 컬럼에 값이 존재하지 않는다는 뜻이다. DML을 이용하여 자료를 다룰 때는 항상 NULL을 주의해야 한다. NUMBER 형 자료를 NULL과 산술 연산하면 결과는 항상 NULL이다.
NULL이 포함될 우려가 있는 컬럼을 사용할 때는 항상 NVL 함수를 이용하여 값을 치환시켜 사용하는 습관을 가져야 한다.
A = NULL 또는 A <> NULL로 사용하면 안 된다. 에러가 발생하지 않지만 원하는 결과가 나올 수 있다.
-- TEMP 테이블에서 HOBBY가 NULL이 아닌 이름을 조회하라.
-- NULL 조건 비교 주의한다.
-- WHERE A IS NULL
-- WHERE A IS NOT NULL
SELECT EMP_NAME
FROM TEMP
WHERE HOBBY IS NOT NULL;
-- IS NOT NULL 과 <> NULL 조건의 결과가 같은지 확인하자.
-- 의도하지 않는 결과가 나타난다.
SELECT EMP_NAME
FROM TEMP
WHERE HOBBY <> NULL;
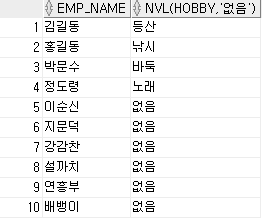
-- TEMP 테이블에서 이름과 HOBBY가 NULL인 사람은 HOBBY를 '없음'이라고 변환하여 조회하라.
-- 문자형 컬럼에 NULL이 포함될 우려가 있다면 다른 특정 문자로 치환하여 사용해야 한다.
-- 숫자형 컬럼에 NULL이 포함될 우려가 있다면 0 또는 1등 적절한 숫자로 치환한 후 연산해야 한다.
SELECT EMP_NAME
, NVL(HOBBY, '없음')
FROM TEMP;
-- TEMP 테이블에서 HOBBY가 NULL인 사람은 HOBBY를 '등산'이라고 변환하였을때 HOBBY가 '등산' 인 이름을 조회하라.
SELECT EMP_NAME
FROM TEMP
WHERE '등산' = NVL(HOBBY, '등산');

4. 컬럼 테이블 ALIAS
컬럼명, 테이블명이 길거나 다른 이유로 다른 이름을 붙여야 할 때 사용하는 것이 ALIAS이다
-- 컬럼 ALIAS
SELECT EMP_ID AS 사번
, EMP_NAME AS 성명
FROM TEMP;
-- 테이블 ALIAS
SELECT A.EMP_ID
, A.DEPT_CODE
, B.DEPT_NAME
FROM TEMP A
, TDEPT B
WHERE A.DEPT_CODE = B.DEPT_CODE;


5. 문자열 결합
두 개 이상의 문자열을 연결하여 하나의 문자열을 만들어낼 때 사용한다. 합성 연산자를 사용하거나 CONCAT 함수를 사용한다.
-- TEMP 테이블에서 이름에 직급을 괄호와 함께 컬럼 ALIAS를 지정해 조회하라.
SELECT EMP_NAME || '(' || LEV || ')' AS 성명
FROM TEMP;
-- TEMP 테이블에서 사번과 이름을 함께 조회하라.
SELECT CONCAT(EMP_ID, EMP_NAME)
FROM TEMP;


6. 질의 결과의 제한
WHERE - 조건절의 시작을 의미한다. 결과 값을 제한하는 역할을 하며 조건이 여러 개 연결될 때는 AND 나 OR로 묶어서 계속 나열한다. 또한 두 개 테이블 이상이 조인이 걸린다면 조인 조건도 WHERE 절에 기술된다. 참고로 PRIMARY KEY로 지정된 컬럼은 자동으로 INDEX가 생성된다.
-- TEMP 테이블에서 취미가 '등산'인 이름을 조회하라.
SELECT EMP_NAME
FROM TEMP
WHERE HOBBY = '등산';
-- TEMP 테이블에서 사번과 이름을 조회하라.
SELECT EMP_ID
, EMP_NAME
FROM TEMP;
-- TEMP 테이블에서 사번이 0보다 큰 사번, 이름을 조회하라.
-- 조건절에 기술된 컬럼이 INDEX가 존재하면 INDEX가 실행계획에 포함되며 자동 정렬된다.
SELECT EMP_ID
, EMP_NAME
FROM TEMP
WHERE EMP_ID > 0;
-- TEMP 테이블에서 취미가 NULL이 아니면서 직급이 '과장'인 사번, 이름, 취미를 조회하라.
SELECT EMP_ID, EMP_NAME, HOBBY
FROM TEMP
WHERE HOBBY IS NOT NULL
AND LEV = '과장';



ORDER BY - 테이블에 저장될 때는 순서가 정해져 있지 않다. 입력한 순서대로 저장이 된다고 생각하는 경우도 있지만 항상 그런 것도 아니다. 테이블에 데이터 양이 적어서 DB 상의 동일 BLOCK 상에 차곡차곡 쌓이거나, 삭제나 변경이 없어 자료가 운 좋게 입력 순서 데이터의 양이 많아지거나 삭제가 빈번히 일어날 경우 무작위로 데이터가 저장되게 된다. 이렇게 순서 없이 저장된 데이터 보고자 할 때 사용하는 것이 ORDER BY이다.
-- TEMP 테이블에서 사번을 ASC 순으로 사번, 이름을 조회하라.
-- ORDER BY 기본값 ASC
SELECT EMP_ID
, EMP_NAME
FROM TEMP
ORDER BY EMP_ID;
-- TEMP 테이블에서 사번을 DESC 순으로 사번, 이름을 조회하라.
SELECT EMP_ID
, EMP_NAME
FROM TEMP
ORDER BY EMP_ID DESC;
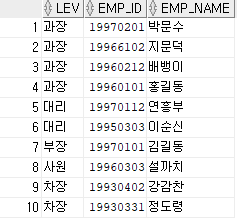
-- TEMP 테이블에서 컬럼순서를 이용하여 정렬하고 직급, 사번, 이름을 조회하라.
-- ORDER BY 컬럼명 대신 컬럼 순서로도 가능하다.
-- 숫자는 컬럼 순서이다.
SELECT LEV
, EMP_ID
, EMP_NAME
FROM TEMP
ORDER BY 1,2 DESC;


7. 연산자
연사자는 WHERE 조건절에서 데이터를 검색 시 조건을 주기 위해 사용한다.
- = : 같은가?
- < : 작은가?
- <= : 작거나 같은가?
- > : 큰가?
- >= : 크거나 같은가?
- <> : 다른가?
- != : 다른가?
- NOT: IN, BETWEEN, LIKE, ANY, ALL, EXISTS 등과 함께 쓰여 연산의 결과를 부정할 때 사용한다.
- LIKE : 값의 일부를 검색할 때 사용한다.
- BETWEEN : 상한 값과 하한 값을 주어 데이터 검색을 하고자 사용한다.
- IN : OR 조건으로 연결된 조건을 한 번에 기술할 때 사용한다.
SELECT EMP_ID
, EMP_NAME
FROM TEMP
WHERE EMP_ID = 19970101;
SELECT EMP_ID
, EMP_NAME
FROM TEMP
WHERE EMP_ID < 19970101;
SELECT EMP_ID
, EMP_NAME
FROM TEMP
WHERE EMP_ID <= 19970101;
SELECT EMP_ID
, EMP_NAME
FROM TEMP
WHERE EMP_ID > 19970101;
SELECT EMP_ID
, EMP_NAME
FROM TEMP
WHERE EMP_ID >= 19970101;
SELECT EMP_ID
, EMP_NAME
FROM TEMP
WHERE EMP_ID <> 19970101;
SELECT EMP_ID
, EMP_NAME
FROM TEMP
WHERE EMP_ID != 19970101;
SELECT EMP_ID
, EMP_NAME
FROM TEMP
WHERE EMP_ID NOT IN(19970101, 19970201);
-- 해당 컬럼을 부정할 때 사용한다.
SELECT EMP_ID
, EMP_NAME
FROM TEMP
WHERE DEPT_CODE LIKE 'A%';
-- 부서코드가 A로 시작되는 조건이다.
SELECT EMP_ID
, EMP_NAME
FROM TEMP
WHERE DEPT_CODE LIKE '%A%';
-- 부서코드가 A가 포함되는 조건이다.
SELECT EMP_ID
, EMP_NAME
FROM TEMP
WHERE DEPT_CODE LIKE '_A____';
-- 부서코드 중 2번째 자리에 A가 위치한 조건이다.
SELECT EMP_ID
, EMP_NAME
FROM TEMP
WHERE EMP_ID BETWEEN 19970101 AND 19971231;
SELECT EMP_ID
, EMP_NAME
FROM TEMP
WHERE EMP_NAME BETWEEN '가' AND '나';
-- WHERE EMP_NAME = '홍길동' OR EMP_NAME = '김길동' 과 같은 의미이다.
SELECT EMP_ID
, EMP_NAME
FROM TEMP
WHERE EMP_NAME IN ('홍길동', '김길동');
8. GROUP BY
GROUP BY는 특정 컬럼이나 값을 기준으로 ROW를 묶어서 데이터를 다룰 때 사용한다. 그룹 함수(MAX
MIN, AVG, SUM, COUNT 등)를 적용할 때 사용한다.
-- TEMP 테이블에서 직급 별로 최고 연봉을 조회하라.
SELECT LEV
, MAX(SALARY)
FROM TEMP
GROUP BY LEV;
-- TEMP 테이블에서 최고 연봉을 조회하라.
-- GROUP BY절 없이 GROUP 함수가 적용 되는 경우이다.
SELECT MAX(SALARY)
FROM TEMP;
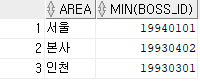
-- TDEPT 테이블에서 지역 별로 최소 BOSS_ID을 조회하라.
SELECT AREA
, MIN(BOSS_ID)
FROM TDEPT
GROUP BY AREA;
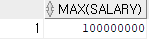
9. HAVING
HAVING은 GROUP BY 된 결과를 제한하고자 할 때 사용한다.
-- TEMP 테이블에서 직급별 평균 연봉이 50000000 큰 조건으로 직급, 평균 연봉을 조회하라.
SELECT LEV
, AVG(SALARY)
FROM TEMP
GROUP BY LEV
HAVING AVG(SALARY) > 50000000;
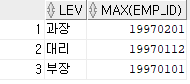
-- TEMP 테이블에서 직급별 사번이 제일 늦은 사람 중 사번이 1997로 시작하는 조건으로 직급, 제일 늦은 사번을 조회하라.
SELECT LEV
, MAX(EMP_ID)
FROM TEMP
GROUP BY LEV
HAVING MAX(EMP_ID) LIKE '1997%';
'데이터베이스 > SQL' 카테고리의 다른 글
| [SQL] 오라클(Oracle) 내장 함수 (숫자 함수) (0) | 2019.06.02 |
|---|---|
| [SQL] 오라클(Oracle) 내장 함수 (문자 함수) (0) | 2019.05.25 |
| [SQL] 오라클(Oracle) 계정 생성 및 권한 부여 (0) | 2019.05.16 |
| [SQL] 로우(Row) VS 레코드(Recode) VS 튜플(Tuple) 차이 (0) | 2019.05.15 |
| [SQL] DELETE, TRUNCATE, DROP 차이 (0) | 2019.03.31 |
- Eclipse
- 제주도 여행
- 자바
- 제주도 3박4일 일정
- Java
- 프로그래머
- javascript
- 오라클 내장 함수
- 개발환경
- 경력관리
- SQL
- 자바스크립트
- 회고
- 리액트
- Tomcat
- spring
- 정렬 알고리즘
- 프로그래머스
- 소프트웨어공학
- Linux 명령어
- 성능분석
- 오라클
- React
- sort algorithm
- effective java
- 리액트 16
- 이직
- Collection
- 리눅스 명령어
- Maven
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
